小电影的网站 PYTHON 爬虫:轻松爬取各类视频资源
在当今数字化的时代,互联网上的视频资源丰富多样。有时候,我们可能会对某些特定类型的视频感兴趣,比如小电影。虽然通过正规渠道获取这些视频是合法和道德的,但有时候我们可能会想要探索一些其他的途径。我将向你介绍如何使用 Python 编写爬虫程序,来抓取小电影网站上的视频资源。
需要注意的是,仅用于学术和教育目的,任何非法活动都将受到法律的制裁。浏览和下载不合法的内容可能涉及到道德和伦理问题,请确保你在法律和道德的框架内使用提供的信息。
准备工作
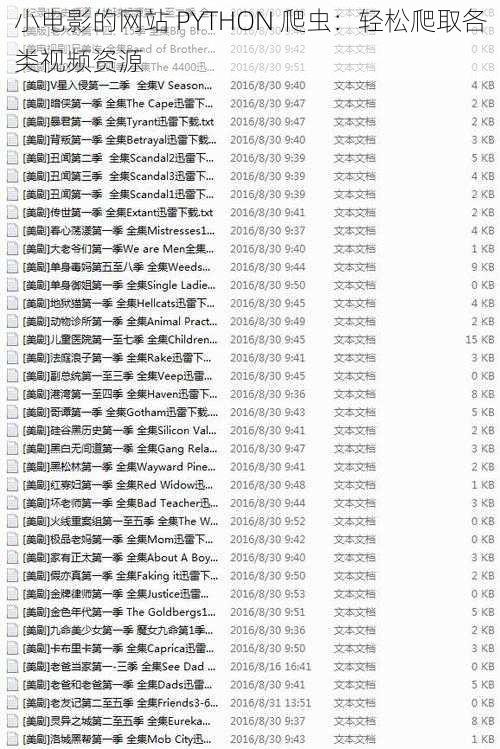
在开始编写爬虫程序之前,你需要做好以下准备工作:
1. Python 编程环境:你需要安装 Python 编程环境,并确保你已经安装了必要的库,如 requests、BeautifulSoup 等。
2. 目标网站分析:了解你要抓取的小电影网站的结构和规则。这包括了解网站的页面布局、视频链接的格式、登录要求等。
3. 合法使用:请确保你在合法的范围内使用爬虫程序,遵守网站的使用条款和法律法规。
爬虫程序的基本原理
爬虫程序的基本原理是模拟浏览器的行为,通过发送 HTTP 请求获取网页内容,并从中提取所需的信息。在这个例子中,我们将重点提取视频链接。
代码实现
以下是一个简单的 Python 爬虫程序的示例代码,用于抓取小电影网站上的视频链接:
```python
import requests
from bs4 import BeautifulSoup
# 定义目标网站
target_url = '
# 发送 HTTP 请求获取网页内容
response = requests.get(target_url)
# 检查请求是否成功
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取视频链接
video_links = soup.find_all('a', href=True)
# 遍历视频链接
for link in video_links:
if 'video' in link['href']:
video_url = link['href']
print(video_url)
else:
print(f'请求失败,状态码: {response.status_code}')
```
在上述代码中,我们首先定义了目标网站的 URL。然后,使用 requests.get() 函数发送 GET 请求获取网页内容。通过检查响应的状态码,我们确保请求成功。如果请求成功,我们使用 BeautifulSoup 库解析网页内容,并使用 find_all() 函数查找所有带有 href 属性的 a 标签。通过遍历这些标签,我们检查链接是否包含 'video' 字符串,如果是,则提取视频链接并打印出来。
请注意,这只是一个简单的示例代码,实际的爬虫程序可能需要更复杂的逻辑来处理各种情况,如处理登录、翻页、解析视频页面等。
注意事项
在编写爬虫程序时,有一些注意事项需要牢记:
1. 遵守网站规则:确保你的爬虫程序遵守目标网站的使用规则,不要进行过于频繁的请求或违反其他限制。
2. 处理反爬虫机制:一些网站可能会实施反爬虫机制,如限制 IP 访问频率、检测 User-Agent 等。你需要了解这些机制并采取相应的措施来规避它们。
3. 合法性和道德性:只抓取合法和道德的内容。不要抓取受版权保护的视频或违反法律法规的内容。
4. 数据存储和处理:合理处理抓取到的数据,避免存储过多不必要的数据或造成服务器负载过高。
5. 错误处理:编写适当的错误处理代码,以处理可能出现的网络错误或其他异常情况。
通过使用 Python 编写爬虫程序,我们可以轻松地抓取小电影网站上的视频资源。在进行任何爬虫活动之前,请确保你已经了解并遵守相关的法律和道德准则。也要注意不要过度依赖爬虫程序,保持对合法和道德行为的尊重。
希望对你有所帮助,如果你有任何进一步的问题或需要更详细的指导,请随时提问。